AliBERT
![]()
Le premier modèle de traitement du langage naturel (NLP) spécialisé dans le domaine biomédical en langue française
AliBERT est un modèle pré-entrainé permettant la détection des entités cliniques (pathologies, anatomie, diagnostics…) dans un rapport médical, qui est de la reconnaissance d’entités (NER en anglais pour Named Entity Recognition).
Lancé fin 2022, le projet AliBERT fait déjà l’objet d’une première publication scientifique.
AliBERT se distingue par sa capacité à accomplir une multitude de tâches, avec un potentiel quasi illimité dès lors qu’il est alimenté avec un ensemble d’exemples annotés, habituellement dans la fourchette de quelques centaines à quelques milliers.

Reconnaissance d’entités*
- Posologie
- Entités cliniques
- Entités oncologiques
- Données personnelles en vue d’une pseudonymisation du document
Classification
de texte**
- Détection d’un lien causal dans une phrase
- Qualification d’un effet secondaire
- Classification d’un type de spécialité
Détection de relations entre deux entités
- médicament ⇾ posologie
- diagnostic ⇾ traitement
- localisation ⇾ latéralité
*Détection de la posologie (médicament, dosage, fréquence), détection d’entités cliniques (anatomie, pathologies, procédures), détection d’entités oncologiques (histologie, grade, stade, localisation du cancer …), détection des données personnelles en vue d’une pseudonymisation du document (nom, prénom, age, adresse, mail, téléphone)
**Détection d’un lien causal dans une phrase, qualification d’un effet secondaire (léger, moyen, sérieux), classification d’un type de spécialité (rapports d’oncologie, rapport d’hospitalisation, prescription, compte rendu pluridisciplinaire)
AliBERT façonne un corpus spécialisé de textes cliniques et biomédicaux, avec une précision inégalée dans le domaine médical en langue française.

AliBERT a été pré-entrainé à partir d’une architecture transformers classique (BERT) sur un corpus de 600 000 documents de type variés. Ce corpus contient, en particulier, des articles de littérature biomédicale, des notices de médicaments, des thèses et quelques rapports cliniques.

AliBERT maîtrise un maximum de mots spécialisés dans les domaines clinique et biomédical grâce à sa brique optimisée permettant le pré-découpage des mots (tokenizer), essentielle à l’encodage de ceux-ci sous forme numérique, surpassant ses contemporains DrBERT et CamemBERT-bio dans ce domaine.

Le pré-apprentissage spécifique du modèle sur un corpus spécialisé en biomédical permet à AliBERT de construire un « dictionnaire » de concepts et de les positionner les uns par rapport aux autres en termes de proximité à la fois sémantique et contextuelle. Un mot sera ainsi à la fois vu selon le sens qu’il porte dans l’absolu et à la fois selon son positionnement dans une phrase.
Par exemple, le mot « tumeur » pourra être rapproché au mot « cancer » si le contexte indique une forme de malignité ou simplement rapproché au mot « excroissance » si le contexte ne parle que d’éléments bénins.
L’exemple ci-dessous donne un aperçu de la capacité d’AliBERT à deviner le bon mot en fonction du contexte :
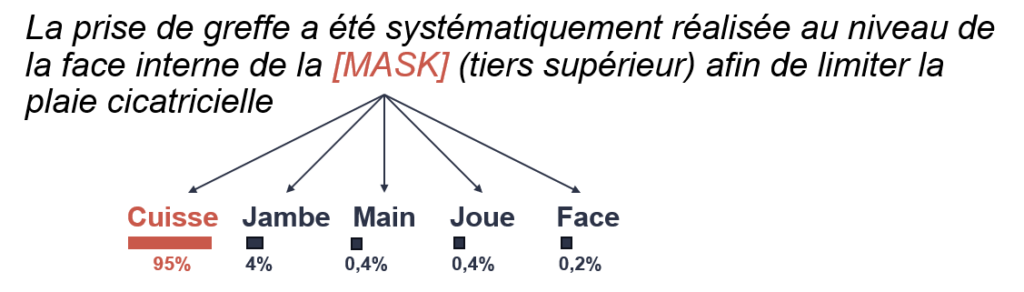
Exemple de prédiction d’un mot dans un texte biomédical.
Le NLP biomédical en français, un domaine peu traité jusqu’à présent
L’avènement des modèles dits « transformers » en 2017, puis plus récemment en 2021, a permis de révolutionner l’analyse de langage (NLP) de manière spectaculaire. De très nombreuses tâches de NLP sont aujourd’hui facilement réalisables à partir de ces technologies avec des performances parfois très élevées. Néanmoins, ces modèles souffrent encore de certaines limites et ne permettent pas toujours de traiter correctement des cas d’usages en français spécifique au domaine de la santé.
- Les LLM (Large Language Model) sont aujourd’hui multilingues, mais les études récentes montrent qu’ils n’atteignent pas forcément les performances des transformers (Ex : BioBERT) dans des domaines techniques comme le langage clinique ou biomédical.
- À l’inverse, les transformers spécifiquement conçus pour traités du langage francophone sont peu nombreux, et s’ils le sont, traitent souvent du langage courant (CamemBERT, JuriBERT, BERTTweetFR).
C’est pour palier ce manque qu’a notamment été créé AliBERT, dont le nom est inspiré d’un médecin du XIXème siècle considéré comme fondateur de la dermatologie en France : Jean-Louis Alibert.
Ce modèle ayant pour double objectif de traiter avec une performance élevée des cas d’usages dans le domaine biomédical et en langue française.